

Following the accident at Leicester City Football Club at the end of last month, all of which was caught on camera, and replayed very publicly, tail rotor failures are back in focus, and for those of us who fly the machines, are very much at the forefront of our minds.
It was following a similar spate of high profile tail rotor incidents and accidents in the 1990s that the UK CAA and the Ministry of Defence co-funded a research project by QinetiQ to study in depth the incidence of tail rotor malfunction across fleets, and consider initiatives to both reduce their frequency, and mitigate their consequences.
The study, Helicopter Tail Rotor Failures CAA Paper 2003/1 was published exactly fifteen years ago, in November 2003. It still represents, to date, the most in depth study of tail rotor malfunctions conducted, and for anybody who is interested in a more in depth understanding of the subject it should be mandatory reading.
How much has changed since then? Has the failure rate reduced significantly with the development of more sophisticated HUMS technology as the report anticipated? How much have training and checking regimes and improved flight simulation evolved to better educate and drill pilots on reacting to and understanding the nuances of different malfunctions in tail rotor control?
The motivation for the 2003 study was the overwhelming evidence that tail rotor failures (TRFs) were occurring at a much greater rate than airworthiness design standards required. This was true for both tail rotor drive and control systems, on both civil and military types.
Data Sources
My first observation as to the effectiveness of the study is the difficulty that was experienced in collecting reliable and comprehensive statistical data. The project examined helicopter TRF statistics covering the period 1971-1994 based on data from the 3 UK MOD accident databases, and civil data were taken from the CAA’s MOR System for the period 1976-1993. Recognising the limited scope of the data set, the study was expanded by obtaining data from global sources. As data from Eastern Block nations were not available, the remaining sources were gathered from the USA, Canada and New Zealand which accounted for over 80% of the remaining known aircraft.
In the absence of worldwide collated accident and incident databases aircraft manufacturers were approached for material to be included in the analysis but they would not release their own figures into the public domain. Presumably, this position has not changed in the intervening 15 years.
What has changed during the period 2003-2018 is the world wide web, global interconnectivity and sharing of information, and our ability to gather data on a whole host of subjects. Certainly, better computerised databases have become more accessible in recent years, take for example the Wiki-style aviation safety database run by the Aviation Safety Network which lists over 20,000 aviation accidents/incidents across aircraft types. Notwithstanding the possibilities that internet has opened up in this field since the 1990s, the ability to search a full database using specific categories such as aircraft type, date fields, and accident causal factors, seem still to be beyond current capabilities.
This is a disappointment given that the very first recommendation of the report was that, “the relevant authorities co-operate to standardise accident and incident classifications, and the details recorded in occurrence reports worldwide.”
The ability to collate occurrence data so that it can be statistically analysed for useful conclusions in the interests of safety and learning is the purpose of any Safety Management System. Although the technology to expand this concept to a global level already exists, and despite the huge untapped potential in safety progress this could represent, the human, organisational, and commercial challenges to making it a reality are still a bridge too far. This is a subject I have touched upon in a previous article titled Aviation safety culture and the paradox of success: Can safety innovation keep pace with technological progress?
The 2003 Study
The UK military airworthiness standard for a TRF (defined as ‘extremely remote’) was set at 1 per every million flying hours. Looking at the statistics for the military types alone, TRF incidents were occurring at an average of over 8 per million flying hours, with the Westland Lynx leading the pack at 33.2 per million flying hours, over 33 times the level considered acceptable.
The expanded database compiled for the 2003 study comprises data from 344 TRF occurrences across civil and military fleets. The civil airworthiness standards define ‘extremely remote’ at an even stricter occurrence rate of 1 in 10 million to 1000 million per flight hour. The study revealed that actual accident rates across the fleets were in the range 9.2-15.8 per million flight hours. The overwhelming evidence demonstrated that TRFs were occurring at rates much higher than the airworthiness standards require.
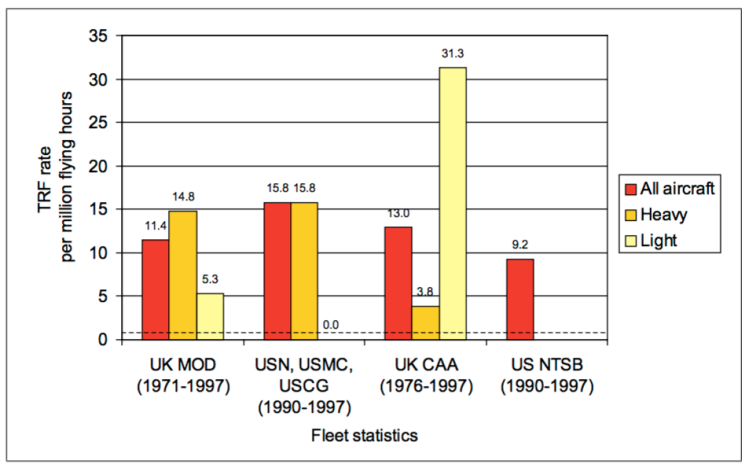
Is this still the case? In the absence of a new study of TRF occurrences in the period since 2003 it is impossible to say definitively, but anecdotal evidence suggests that there has not been a significant decline in these occurrences with the introduction of new aircraft and technologies in the past 15 years. Within the UK military fleet a few significant TRF incidents spring to mind in the last 7 years alone.
The development of Health and Usage Monitoring Systems (HUMS)
The 2003 study focused on HUMS in some depth as a key technology for monitoring TR health. At the time of the occurrences studied (1970s-1990s) HUMS was yet to be born or was still in its infancy.
One of the findings of the study was that failure of the drive system accounts for approximately one third of all TRF occurrences and fatalities. It went on to conclude that, by conservative estimate, 49% of TRF caused by failure of the drive system, and 18% of TRFs overall could have been prevented by HUMS, and that those figures could be increased by another 15% and 5% respectively with further development of HUMS technology. A more up to date study of TRF statistics would allow us to check up on the accuracy of that prediction.
There is good evidence that HUMS analysis has had an important role to play in preventing potentially catastrophic TRF accidents. This was highlighted by an incident in the North Sea in December 2016 when an S92 suffered a TR pitch shaft bearing failure over a platform helideck. The warning signs were picked up on HUMS data, but systemic and human factors intervened to prevent the anomaly being identified, and the aircraft was released back into service, leading to the incident. For a good short case study on this incident by Aeroassurance, click here.

This occurrence has been a catalyst for further momentum in the development of HUMS, making the case for advancing the concept into real time HUMS (See article). Real-time HUMS echoes one of the 2003 report’s recommendations with respect to the future potential for HUMS which says that, “”further work should be conducted to define an approach for the presentation of in flight information.”
Furthermore, it goes on that, “In the longer term consideration should be given to providing an intelligent cockpit warning system that prioritises warnings, presents immediate actions, guides the pilot through a sequence of steps, and makes supporting information available”. We are not there yet.
Training, emergency procedures and advice to aircrew
The study found that statistically the largest causes of TRF are the TR either striking or being struck by an object, which together account for approximately one half of all TRF occurrences and fatalities. Of course, these are not airworthiness incidents at all. As might be expected, the study also confirmed that a disproportionately large number of occurrences (51%) are associated with high torque phases of flight.
In terms of training, two quick lessons can immediately be drawn from this data, namely that situational awareness of the tail, and the flight condition in which you chose to spend time, are two areas where better training and awareness could help to keep us safe. To this we could add FOD and loose article awareness, as it appears that a recent fatal accident in New Zealand on 18th October of this year could have been caused by an item of clothing being sucked out of the cockpit and going through the tail rotor. (See article).
Soberingly, the report concluded that for a TR drive failure in forward flight with a pilot intervention time of 2 seconds, (considered to be a realistic estimate for a well-trained pilot) the outcome is a transient sideslip that is likely to be beyond the structural limits of the aircraft, and would require a control response by the pilot that will cause the rotor speed to exceed the transient limits and make a successful outcome very unlikely. Similarly, the hover trials showed that there is little that can be done to avoid the spin entry caused by a drive failure. Recovery from a high power TR control failure was also very difficult, with the chances of recovery without significant damage concluded to be low.

In many cases the trials identified that the difference between a successful and unsuccessful outcome turned on the speed with which the pilot could recognise a TRF and therefore their subsequent reaction time. If fast enough it might prevent the aerodynamic response to the loss of anti-torque taking the aircraft beyond its structural limits. This conclusion makes the quality of training and technical advice on different types of failure and individual aircraft responses to them amongst the most critical factors in recovering from a TR related incident.
Acknowledging this, one of the key recommendations of the report was that manufacturers should be required to analyse the effect of TRFs in their aircraft types, and to provide more in depth advice in terms of handling and emergency procedures. The importance of this also stemmed from the evidence that arose about complexities and differences in aircraft responses across different types. A one size fits all philosophy that ‘a helicopter is a helicopter is a helicopter’ does not apply when it comes to dealing with TR malfunctions. The trials showed how significantly different the response to ‘the same’ malfunction can be according to aircraft type, flight regime – and crucially – the immediate response of the pilot to the initial symptoms of the failure. Thus, knowing how to recognise these, and respond correctly for your aircraft could determine a life or death outcome.
Also highlighted is the variation and standard of advice currently given in Aircrew or Flight Manuals. In many cases (and my current type, the AS365N2 is a case in point) there is no handling advice to the crew whatsoever as to the characteristics of the aircraft following a drive failure, and TR control failures are not referred to at all. The key message from the research is that manufacturers should be mandated to provide validated, and more in depth advice on TR malfunction handling for all types. This includes that:
- It should make clear whether the use of a power and speed combination is appropriate during the recovery from a TRDF.
- There should be information on techniques required to control the descent.
- The loss of tail pylon/TR components should be identified as a source of possible aircraft pitch control problems.
- Unusual vibrations emanating from the TR area should be identified as being indicative of a possible TR problem and should lead to selection of minimum power setting when in forward flight, or a landing and shutdown for technical investigation if in the hover.
- Unusual pedal positions should be identified as a possible impending TRF condition, leading to the same actions as above.
- The effects of a TR control circuit disconnect on the TR pitch condition should be identified.
- Where appropriate to type, the benefit of varying the main rotor speed in the hover following a TRCF should be advised.
- There should be a requirement for the manufacturer to identify the possible failure modes of the TR control circuit, and the impact of TRFs on the anti-torque moment supplied by the TR so that appropriate advice can be generated.

For some of the larger, and more modern types, there is no doubt that the quality and quantity of information available to aircrew has improved significantly in recent years, as has the accessibility of more in depth sources. For example, the philosophy of the Flight Crew Operating Manual as a supplement to the Flight Manual which communicates the manufacturer’s guidelines to operators for enhancing operational safety during routine and abnormal situations, is evidence of this kind of advance. However, the standard of advice still varies greatly depending on both manufacturer and type, and this level of guidance to flight crews is not always the norm.
Simulator Training
The fidelity of simulator training is discussed in some depth. This is another area in which technology has advanced in leaps and bounds since the turn of the century, as has its now far more widespread use by operators. However there is still the problem of how to model effectively a flight response – and gather data – for something that is usually so far outside of the flight envelope that it cannot be safely recreated in flight.

The recommendation that TRF diagnosis and recovery training in a simulator is part of normal company training policy is accompanied by the warning that the provision of inappropriate training due to poor modelling in the simulator or poor type-specific advice from instructors could exacerbate the problems encountered during emergencies.
Summary
On reading the report it seems reasonable to conclude that fifteen years later there have been some significant advances made, especially with respect to the quality of training and advice on TR malfunctions available to aircrew, and in the extent that HUMS is now a factor in providing early warning of technical, maintenance, or design failures. However, it is also fair to conclude that there is still much more that could be done, and as accidents such as those in Leicester seem set to show us, that tail rotor components can still fail, and slip through the cracks of airworthiness and design standards at a higher frequency than the industry should be comfortable with.
Remembering that 50% of TRFs are caused by impact of the TR against another object, how we choose to operate our aircraft with respect to the tail should be at the forefront of our minds. The flight profiles that we choose are more often determined by OEI considerations and performance margins than by considering the probability of suffering a tail rotor malfunction. Despite much ill-informed debate about the choice of departure profile from the stadium in Leicester, the prioritisation of OEI considerations over other serious malfunctions does raise some interesting questions for how the industry assesses the risks of flight as a whole.
It may be fifteen years old this month, but a thorough read of this CAA paper CAA Paper 2003/1 will have something to teach every pilot out there, and at least should give you cause to spare a thought for taking into account more than just your single engine considerations the next time you pick an approach, establish a hover, or manoeuvre towards a confined area. If nothing else, let it inspire you to go away and find out more about the tail rotor characteristics and failure modes of your own machine.
For those who don’t have the stamina to wade through the full 255 page CAA Paper, then for a short read I recommend jumping straight to Appendix B, Tail Rotor Failures- Advice and considerations, by Steve O’Collard for an excellent summary of the trials that were carried out and generic advice and considerations on tail rotor failures to raise awareness within the professional piloting community.
